Indexing #indexing
Indexing is how search engines store your pages so they can be returned in results. A page that is crawled but not indexed earns nothing. The guides below explain how indexing decisions are made, why pages get excluded, and how canonical tags, sitemaps, and noindex directives shape what ends up in the index.
10 posts

Organic Traffic Dropped? A Calm Diagnostic Playbook
Your organic traffic fell and the graphs look scary. Here is a calm, step by step way to find the real cause before you change a single thing.

Discovered, Currently Not Indexed: Why It Happens and How to Fix It
Google found your pages but will not index them, and they have sat that way for weeks. Here is what 'Discovered, currently not indexed' actually means, how it differs from 'Crawled, currently not indexed', and a crawl-based way to fix the real cause.
Why Low-Value Pages Get Crawled More (and How to Stop It)
Search engines often spend most of your crawl budget on the pages that matter least. Why low-value URLs attract crawlers, how to find them, and how to redirect that attention to the pages you actually want indexed.

Why Pages Get Deindexed (and How to Diagnose It with a Crawl)
Hundreds of pages dropped from Google overnight and you have no idea why. Here is what 'deindexed' actually means, the eight causes that explain almost every case, and a 15 minute crawl-based triage to find yours.
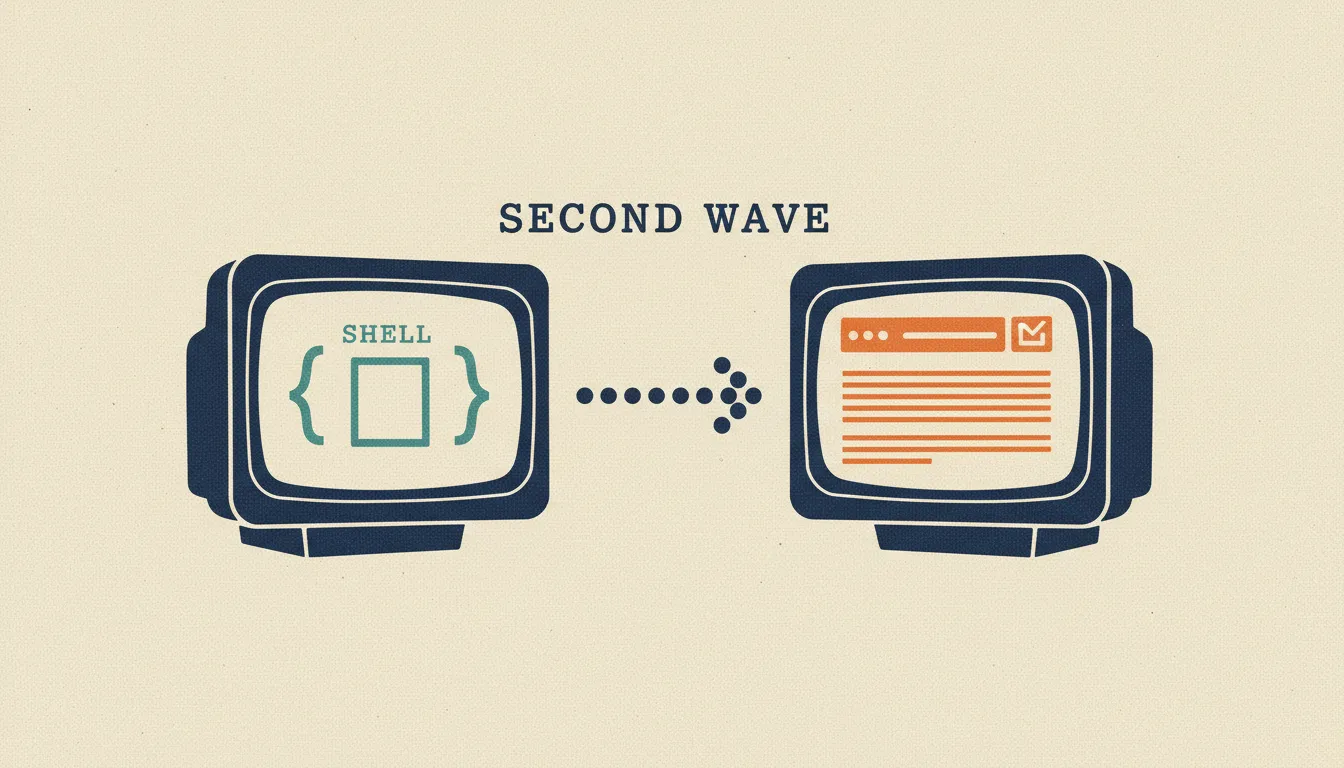
JavaScript SEO and Rendering: How Search Engines See Your Modern App
How Google and AI crawlers actually render JavaScript, the two wave indexing model, when to choose CSR, SSR, SSG, or ISR, and the patterns that quietly break indexing.

Hreflang Implementation Guide: Three Methods, x-default, and Five Common Mistakes
How to implement hreflang correctly for multilingual sites. The three placement options, the x-default tag, the relationship with canonical, and the five mistakes that quietly break it.

XML Sitemaps at Scale: Build, Split, and Validate Without Quiet Errors
An XML sitemap tells crawlers which URLs you want indexed. Learn the spec, the 50,000 URL split rule, what belongs in or out, and how to validate yours.

Canonical Tags Explained: Stop Duplicate Content Hurting Your Rankings
Canonical tags tell search engines which URL to index when duplicates exist. Learn how to use rel canonical correctly and avoid common mistakes.

Crawl Budget for Ecommerce: Stop Wasting Googlebot on Filters
Faceted navigation, product variants, and infinite filters drain crawl budget on ecommerce sites. Here is how to reclaim it for pages that sell.

Crawl Budget Optimization: Make Search Engines Index What Matters
Learn what crawl budget is, why it matters for SEO, and practical strategies to optimize how search engines crawl and index your website.