Indexación #indexing
La indexación es cómo los buscadores almacenan tus páginas para devolverlas en los resultados. Una página rastreada pero no indexada no genera nada. Las guías a continuación explican cómo se toman las decisiones de indexación, por qué se excluyen páginas y cómo las etiquetas canonical, los sitemaps y las directivas noindex moldean lo que termina en el índice.
10 artículos

¿Cayó el tráfico orgánico? Un manual de diagnóstico sereno
Su tráfico orgánico bajó y las gráficas asustan. Aquí tiene una forma serena, paso a paso, de hallar la causa real antes de cambiar nada.

Descubierta, actualmente sin indexar: por qué pasa y cómo solucionarlo
Google encontró tus páginas pero no las indexa, y llevan semanas así. Qué significa de verdad 'Descubierta, actualmente sin indexar', en qué se diferencia de 'Rastreada, actualmente sin indexar' y cómo resolver la causa real con un rastreo.
Por qué las páginas de bajo valor se rastrean más (y cómo evitarlo)
Los motores de búsqueda suelen gastar la mayor parte de su presupuesto de rastreo en las páginas que menos importan. Por qué las URL de bajo valor atraen a los rastreadores, cómo encontrarlas y cómo dirigir esa atención a las páginas que de verdad quiere indexar.

Por qué Google desindexa páginas (y cómo diagnosticarlo con un rastreo)
Cientos de páginas desaparecen de Google de la noche a la mañana y no sabes por qué. Qué significa realmente 'desindexada', las ocho causas que explican casi todos los casos y un triaje basado en rastreo de 15 minutos para encontrar la tuya.
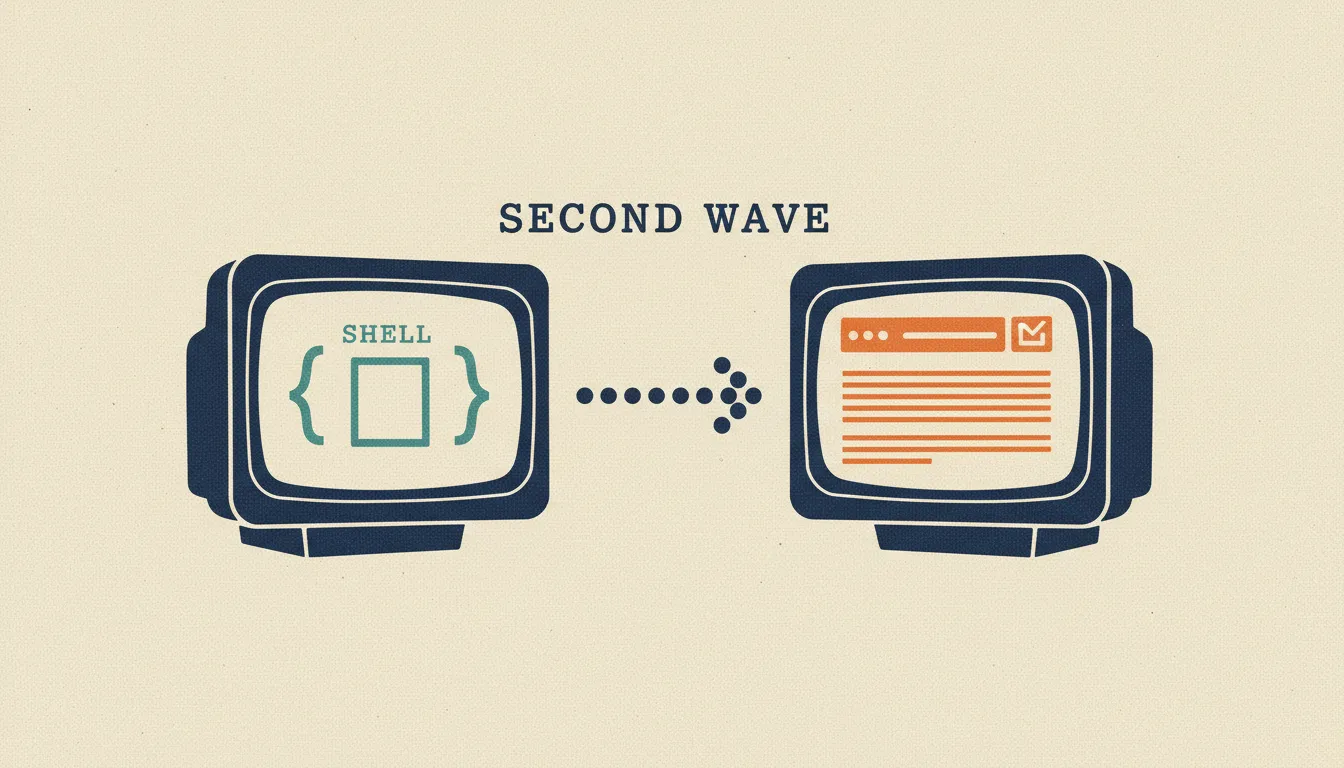
JavaScript SEO y rendering: lo que los buscadores ven en tu app moderna
Cómo Google y los crawlers de IA renderizan JavaScript de verdad, el modelo de indexación en dos olas, cuándo elegir CSR, SSR, SSG o ISR, y los patrones que rompen la indexación en silencio.

Guía de implementación de hreflang: tres métodos, x-default y cinco errores comunes
Cómo implementar hreflang correctamente en sitios multilingües. Las tres opciones de colocación, el tag x-default, la relación con canonical y los cinco errores que lo rompen en silencio.

XML Sitemaps a Escala: Construir, Dividir y Validar Sin Errores Silenciosos
Un sitemap XML indica a los crawlers qué URLs quiere indexar. Aprenda la especificación, la regla de división de 50.000 URLs y cómo validar el suyo.

Etiquetas canonical explicadas: cómo evitar que el contenido duplicado dañe sus rankings
Las etiquetas canonical indican a los buscadores qué URL indexar cuando hay duplicados. Aprenda a usar rel canonical correctamente y evite errores comunes.

Crawl Budget para Ecommerce: No Desperdicie Googlebot en Filtros
La navegación facetada, las variantes de producto y los filtros infinitos consumen el crawl budget en ecommerce. Recupérelo para las páginas que venden.

Optimización del crawl budget: haga que Google indexe lo importante
Aprenda qué es el crawl budget, por qué importa para el SEO y estrategias prácticas para optimizar cómo los motores rastrean su sitio web.