Crawling #crawling
Crawling is the first step before indexing: search engines and AI bots discover URLs and fetch them. Slow, broken, or unreachable pages waste crawl budget and delay or prevent indexing. These guides cover how crawlers work, how to control them with robots.txt and internal links, and how to audit your site like a crawler does.
9 posts

Organic Traffic Dropped? A Calm Diagnostic Playbook
Your organic traffic fell and the graphs look scary. Here is a calm, step by step way to find the real cause before you change a single thing.

Discovered, Currently Not Indexed: Why It Happens and How to Fix It
Google found your pages but will not index them, and they have sat that way for weeks. Here is what 'Discovered, currently not indexed' actually means, how it differs from 'Crawled, currently not indexed', and a crawl-based way to fix the real cause.
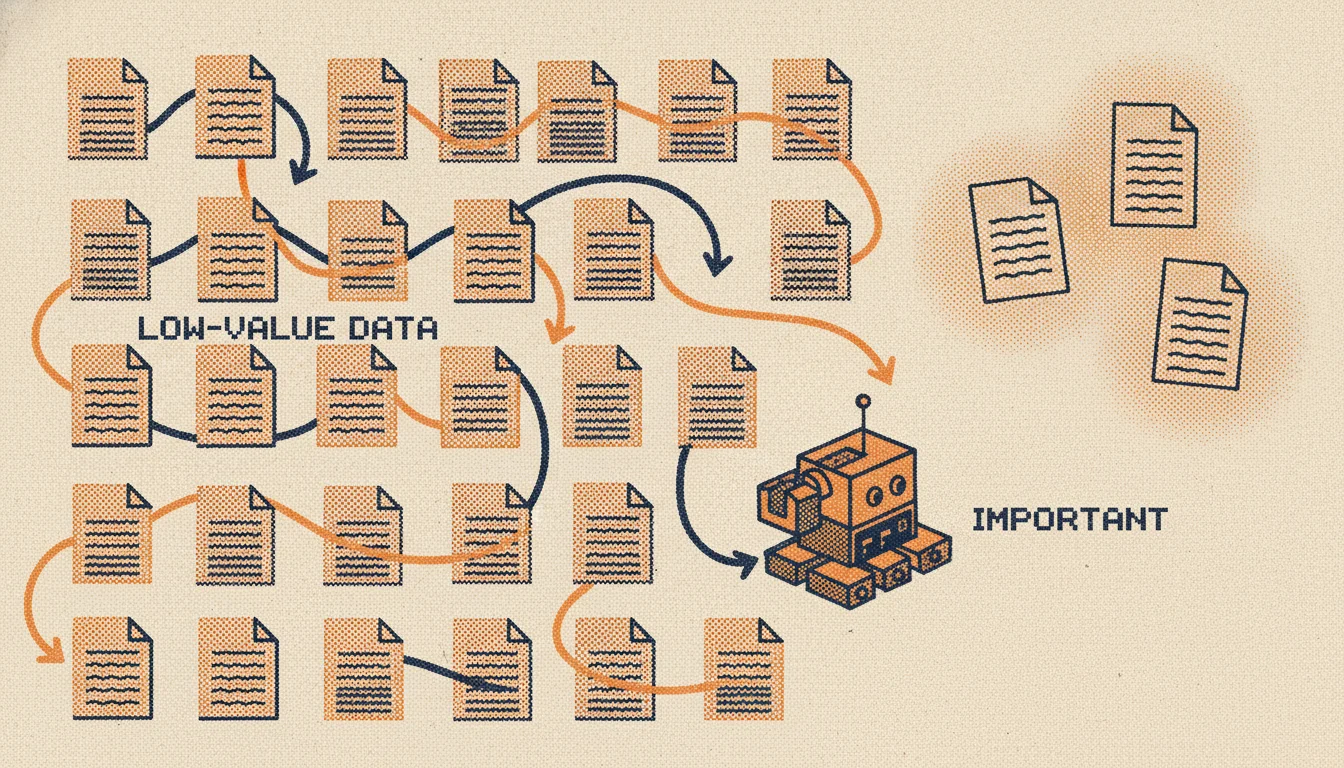
Why Low-Value Pages Get Crawled More (and How to Stop It)
Search engines often spend most of your crawl budget on the pages that matter least. Why low-value URLs attract crawlers, how to find them, and how to redirect that attention to the pages you actually want indexed.

Why Pages Get Deindexed (and How to Diagnose It with a Crawl)
Hundreds of pages dropped from Google overnight and you have no idea why. Here is what 'deindexed' actually means, the eight causes that explain almost every case, and a 15 minute crawl-based triage to find yours.

XML Sitemaps at Scale: Build, Split, and Validate Without Quiet Errors
An XML sitemap tells crawlers which URLs you want indexed. Learn the spec, the 50,000 URL split rule, what belongs in or out, and how to validate yours.

The Complete Guide to robots.txt: Rules, Examples, and AI Crawlers
robots.txt controls what search engines and AI crawlers can access. Learn the syntax, common patterns, and how to handle GPTBot, ClaudeBot, and PerplexityBot.

What Are SEO Crawlers? The Complete 2026 Guide
What SEO crawlers are, how they work, what they check, and how to use crawl data to improve your site. The complete 2026 guide to crawling for technical and AI SEO.
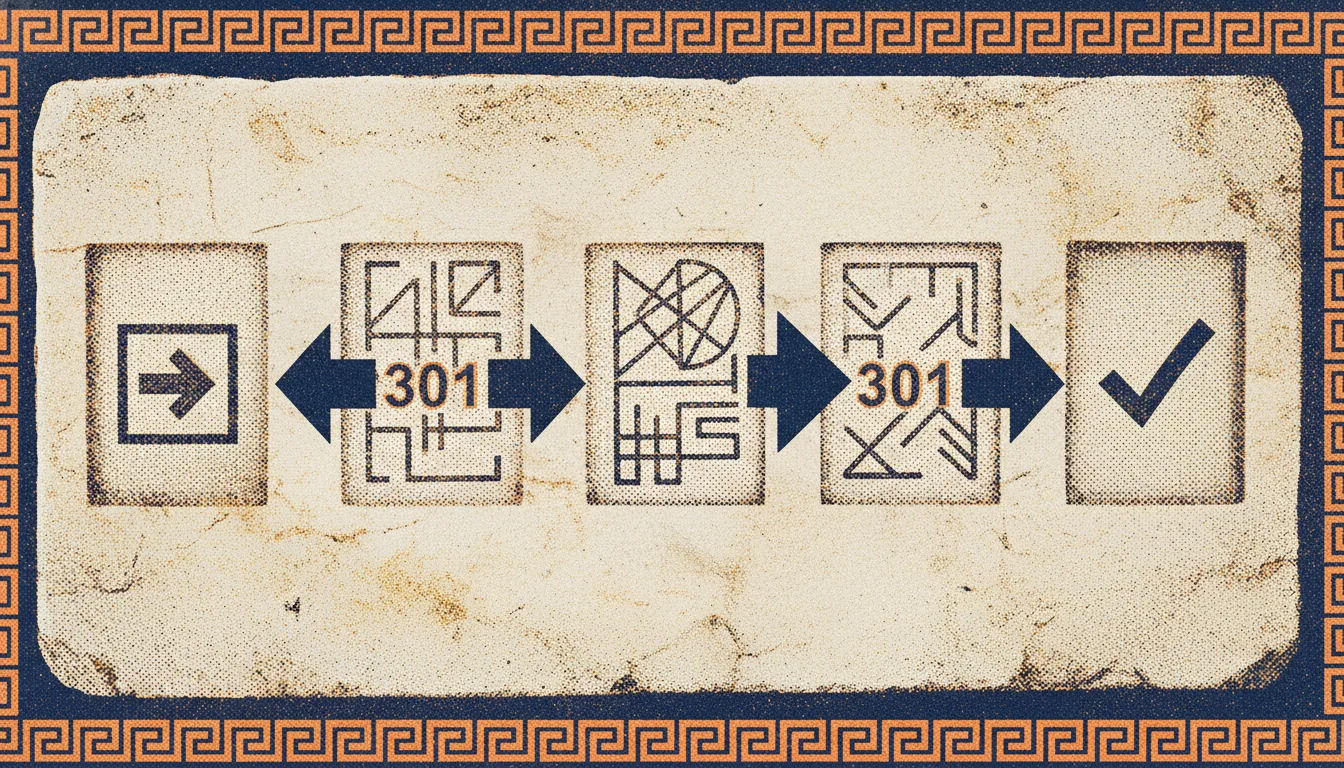
What Are Redirect Chains and How to Fix Them
Redirect chains slow down crawling, waste link equity, and confuse search engines. Learn what they are, why they happen, and how to find and fix them.

How to Find and Fix Broken Links on Your Website
Broken links hurt SEO and user experience. Learn how to find, categorize, and fix broken links on your website with practical strategies.