Rastreo #crawling
El rastreo es el primer paso antes de la indexación: los buscadores y bots de IA descubren URLs y las recuperan. Las páginas lentas, rotas o inaccesibles desperdician presupuesto de rastreo y retrasan o impiden la indexación. Estas guías cubren cómo funcionan los crawlers, cómo controlarlos con robots.txt y enlaces internos, y cómo auditar tu sitio como lo hace un crawler.
9 artículos

¿Cayó el tráfico orgánico? Un manual de diagnóstico sereno
Su tráfico orgánico bajó y las gráficas asustan. Aquí tiene una forma serena, paso a paso, de hallar la causa real antes de cambiar nada.

Descubierta, actualmente sin indexar: por qué pasa y cómo solucionarlo
Google encontró tus páginas pero no las indexa, y llevan semanas así. Qué significa de verdad 'Descubierta, actualmente sin indexar', en qué se diferencia de 'Rastreada, actualmente sin indexar' y cómo resolver la causa real con un rastreo.
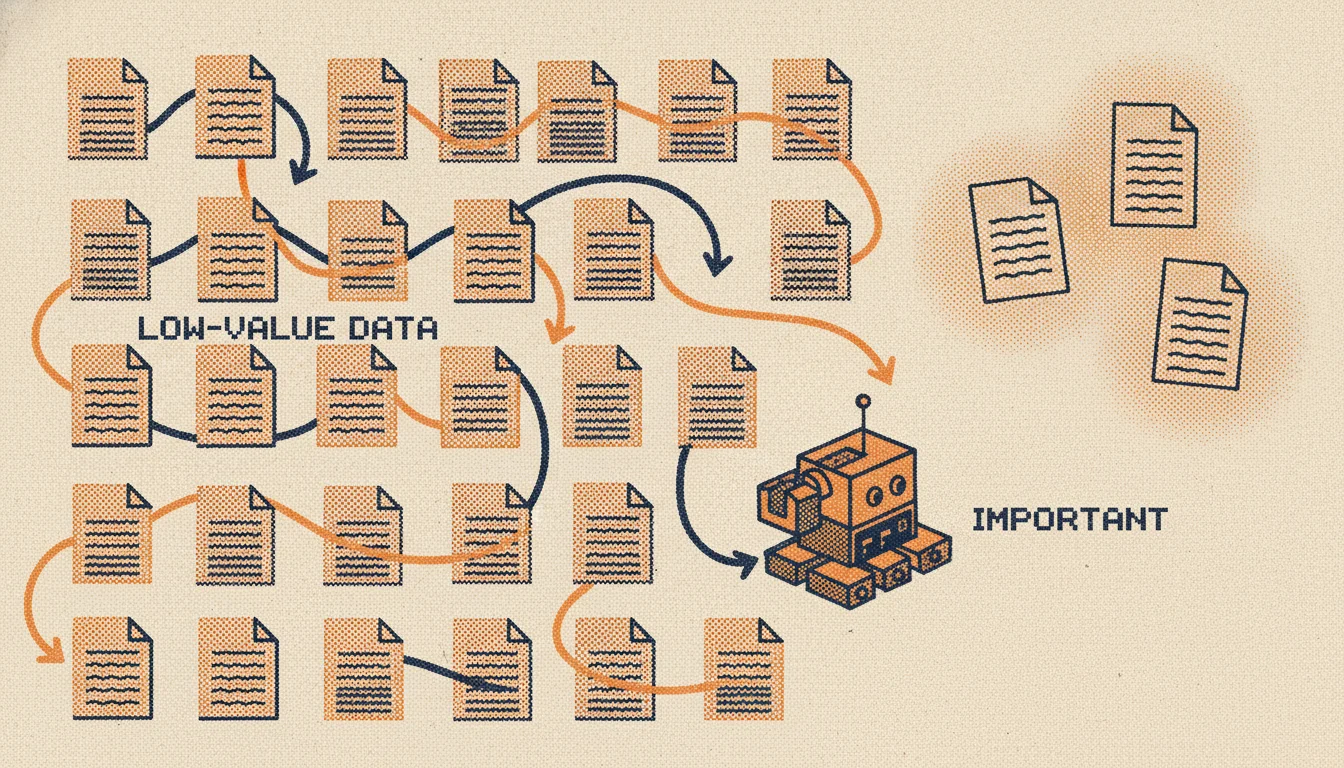
Por qué las páginas de bajo valor se rastrean más (y cómo evitarlo)
Los motores de búsqueda suelen gastar la mayor parte de su presupuesto de rastreo en las páginas que menos importan. Por qué las URL de bajo valor atraen a los rastreadores, cómo encontrarlas y cómo dirigir esa atención a las páginas que de verdad quiere indexar.

Por qué Google desindexa páginas (y cómo diagnosticarlo con un rastreo)
Cientos de páginas desaparecen de Google de la noche a la mañana y no sabes por qué. Qué significa realmente 'desindexada', las ocho causas que explican casi todos los casos y un triaje basado en rastreo de 15 minutos para encontrar la tuya.

XML Sitemaps a Escala: Construir, Dividir y Validar Sin Errores Silenciosos
Un sitemap XML indica a los crawlers qué URLs quiere indexar. Aprenda la especificación, la regla de división de 50.000 URLs y cómo validar el suyo.

La Guía Completa de robots.txt: Reglas, Ejemplos y Crawlers de IA
robots.txt controla a qué pueden acceder motores y crawlers de IA. Aprenda sintaxis, patrones comunes y cómo gestionar GPTBot, ClaudeBot y PerplexityBot.

¿Qué son los crawlers SEO? La guía completa para 2026
Qué son los crawlers SEO, cómo funcionan, qué revisan y cómo usar los datos de rastreo para mejorar tu sitio. La guía completa de 2026 sobre rastreo para SEO técnico y de IA.
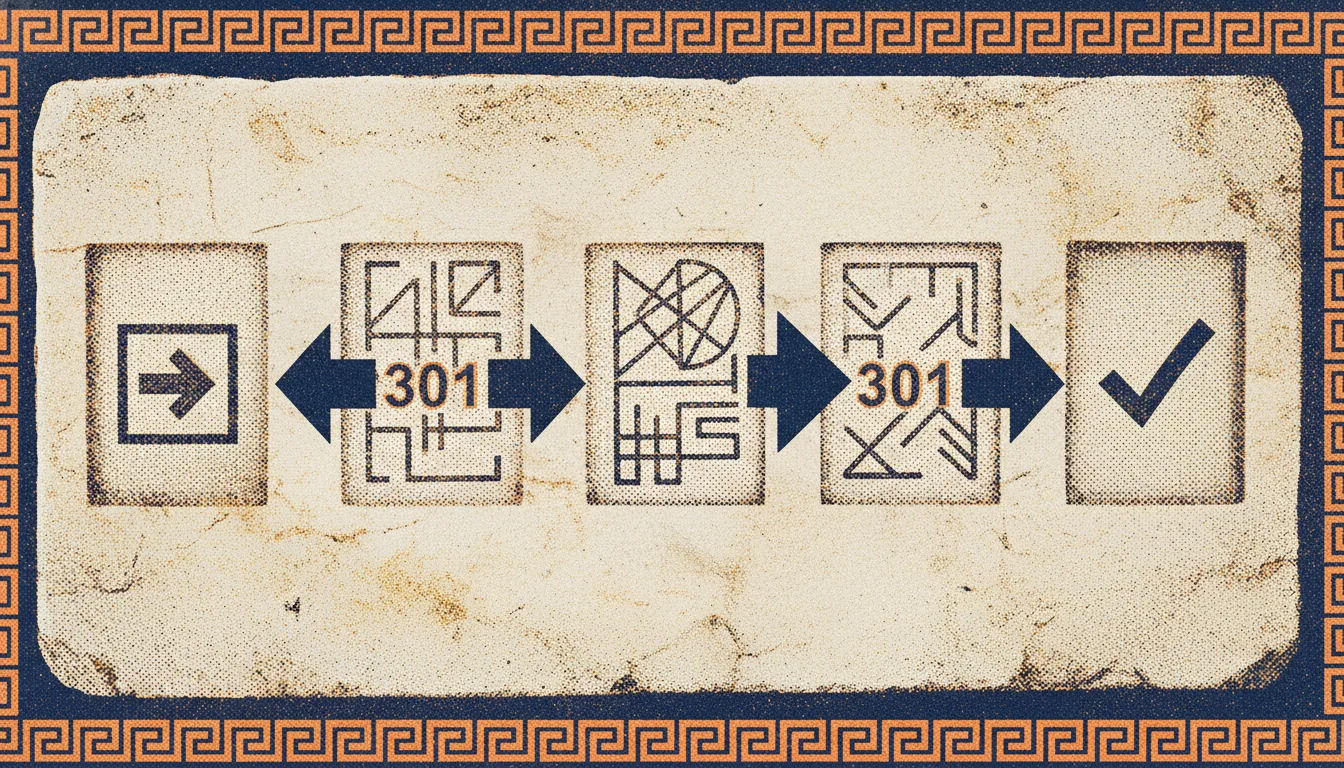
Qué son las cadenas de redirección y cómo arreglarlas
Las cadenas de redirección ralentizan el rastreo, desperdician autoridad de enlaces y confunden a los buscadores. Aprenda qué son, por qué ocurren y cómo encontrarlas y repararlas.

Cómo encontrar y arreglar enlaces rotos en su sitio web
Los enlaces rotos dañan el SEO y la experiencia de usuario. Aprenda a encontrarlos, categorizarlos y arreglarlos con estrategias prácticas.