Crawl Budget para Ecommerce: No Desperdicie Googlebot en Filtros

Una tienda de 5.000 productos suena pequeña hasta que cuenta las URLs. Añada cinco facetas de filtro, tres opciones de orden, paginación y variantes de color, y Googlebot se encuentra de pronto con medio millón de URLs para elegir. La mayor parte de ese inventario no es contenido que quiera tener indexado, y cada petición gastada ahí es una petición que no llega al nuevo SKU que lanzó esta mañana. Este artículo cubre las seis formas en las que un ecommerce pierde crawl budget y los arreglos que resisten cuando llega el tráfico real.
Por qué los ecommerce desperdician crawl budget de forma distinta
Un sitio de contenido tiene aproximadamente una URL por página única. Un ecommerce no. Cada página de producto puede dividirse en variantes de talla, color y material. Cada página de categoría puede dividirse en vistas filtradas, órdenes de clasificación y paginación. Cada promoción puede añadir un parámetro de seguimiento. Cuando suma la búsqueda interna y los enlaces de afiliados, el número de URLs puede ser entre 50 y 100 veces mayor que el número de páginas que realmente traen tráfico orgánico.
Googlebot no sabe cuáles de esas URLs merecen una visita. Las descubre a través de enlaces internos, sitemaps y backlinks externos, y luego planifica los rastreos según con qué frecuencia cambia cada una y cuán importante parece. Si su sitio sigue apuntando a Googlebot hacia combinaciones de filtros, él sigue volviendo a ellas. Mientras tanto, sus páginas de producto reales esperan en la cola.
La segunda complicación es la carga del servidor. Las plataformas de ecommerce como Magento, Shopify Plus y las grandes instalaciones de WooCommerce son más pesadas que un blog. El carrito, el inventario y la lógica de personalización se ejecutan en cada petición. Cuando los tiempos de respuesta suben, Google reduce automáticamente su velocidad de rastreo. La propia guía de Google para sitios grandes confirma que un servidor lento limita directamente cuántas páginas se rastrean al día.
El coste se acumula a lo largo del calendario. Un producto nuevo lanzado el lunes puede no indexarse hasta el fin de semana siguiente. Una colección de temporada que sale tres semanas antes del inicio de la temporada puede perder la ventana de tráfico por completo. Para un sitio de contenido, una indexación lenta es una molestia. Para una tienda, es ingreso que se pierde.
Si es nuevo en el tema, cómo funciona realmente el crawl budget cubre los fundamentos. El resto de este artículo asume que conoce las bases y busca el manual específico para ecommerce.
Los seis asesinos del crawl budget en los ecommerce
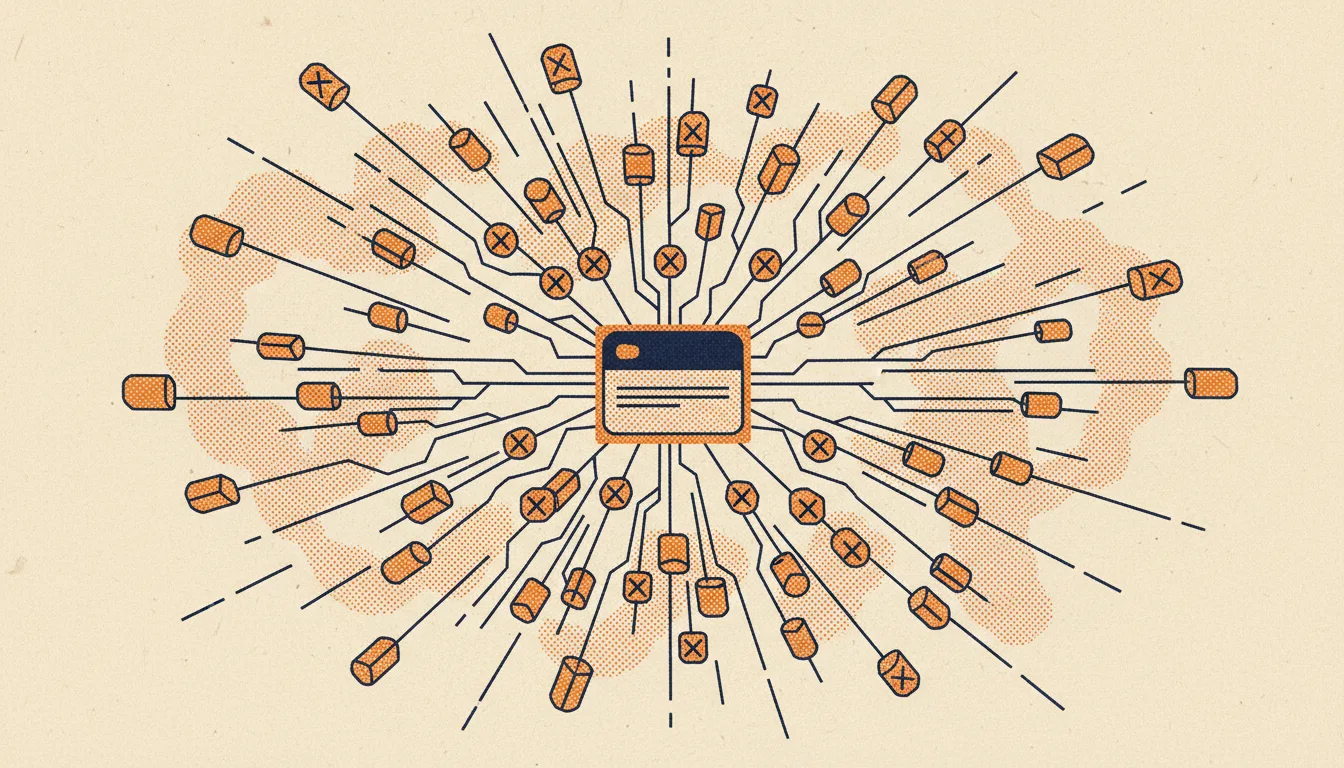
Todo ecommerce pierde más o menos en los mismos sitios. Los nombres de los archivos y las plataformas cambian, pero los patrones son los mismos.
La explosión de la navegación facetada
La navegación facetada permite al comprador acotar una categoría por talla, color, marca, rango de precio y material. Cada faceta parece inofensiva por sí sola. El problema es la combinatoria. Una categoría de chaquetas con cinco facetas y cuatro opciones cada una produce 1.024 variaciones de URL, y eso antes de añadir el orden o la paginación.
La mayoría de plataformas enlazan a cada faceta desde la barra lateral por defecto. Googlebot sigue esos enlaces e indexa cada página de resultado como una URL distinta. Desde su punto de vista, category/jackets?color=red&size=m&brand=northface&sort=price es una página diferente a category/jackets?color=red&size=m&brand=northface. Multiplique eso por cada categoría del sitio y el número de URLs asciende a los millones.
La solución no es quitar los filtros. Los compradores los necesitan. La solución es decidir qué combinaciones merecen exponerse a los motores de búsqueda y tratar el resto solo como una función para el usuario, invisible para los bots.
URLs propias para variantes de producto
Muchas plataformas asignan a cada combinación de color y talla su propia URL. Una camisa disponible en diez colores y cinco tallas se convierte en cincuenta URLs, todas con contenido casi idéntico. Google ve cincuenta duplicados y gasta cincuenta peticiones de rastreo en lo que debería ser una sola página de producto.
Peor aún: las URLs de las variantes suelen competir entre sí por la misma búsqueda. Una búsqueda por el nombre de la camisa puede devolver cualquiera de las cincuenta, o ninguna, porque Google no sabe qué variante posicionar.
Algunas variantes merecen su propia URL. Si “zapatillas de correr rojas” tiene demanda de búsqueda medible, la variante roja puede justificar una página independiente. La mayoría de variantes no llegan a ese umbral y deberían consolidarse en el producto padre.
Búsqueda interna y parámetros de orden
Las páginas de búsqueda interna como ?q=jacket generan un espacio infinito de URLs. Cualquier consulta que un comprador escriba se convierte en una URL rastreable si se enlaza desde algún sitio, incluidos los paneles de analítica o los informes de afiliados. Los parámetros de orden hacen lo mismo. ?sort=price_asc, ?sort=price_desc, ?sort=newest y ?sort=popularity producen cada uno URLs distintas que muestran el mismo contenido en otro orden.
A Googlebot no le importa el orden. Le importa que existan cuatro URLs donde una sería suficiente. Si su plataforma además añade parámetros de idioma o moneda, la cifra se multiplica aún más.
Secuencias de paginación en páginas de categoría
Una categoría con 400 productos y 20 productos por página produce 20 vistas paginadas. La página 1 puede tener valor. La página 14 probablemente no. La antigua pista rel=next/prev ya no la reconoce Google como señal de indexación, así que no hay una forma simple de decirle que esas páginas pertenecen a una serie.
Las colas largas de paginación también crean productos huérfanos. Un producto que solo aparece en la página 17 de una categoría se descubre muy poco. Googlebot quizá visita esa página una vez al mes y luego se olvida de ella hasta que otra cosa la vuelve a traer a la luz.
Productos sin stock y descatalogados
Las páginas de productos sin stock viven en una zona ambigua. Si las elimina, pierde la autoridad de enlaces que han acumulado. Si las mantiene como respuestas con estado 200 y contenido vacío, Googlebot las sigue rastreando y se pregunta por qué no muestran nada. Si devuelve 404 de forma demasiado agresiva, pierde la oportunidad de recuperar compradores cuando el stock vuelve.
Los productos descatalogados son peores. Un sitio que rota su catálogo a menudo acaba con miles de URLs muertas que todavía reciben enlaces desde antiguas páginas de categoría, campañas de email y redes de afiliados. Cada una es una petición de rastreo que no produce valor para el índice.
IDs de sesión y parámetros de seguimiento
?utm_source=, ?fbclid=, ?gclid=, ?affiliate_id= y los tokens de sesión de la plataforma crean todos variantes de la misma página. Si sus feeds de producto incluyen códigos de seguimiento en las URLs, cada clic de afiliado crea una nueva URL en la red. Googlebot las encuentra a través de los backlinks y las rastrea como si fueran contenido nuevo.
Los ecommerce reciben este golpe con más fuerza que los sitios de contenido porque sus programas de marketing generan muchas más variantes con parámetros, y esas variantes viajan por correos, anuncios pagados y redes de socios.
Cómo auditar el desperdicio de crawl budget en su ecommerce
No se puede arreglar lo que no se ve. Antes de tocar nada en robots.txt o en las etiquetas canonical, haga un mapa de lo que Googlebot hace realmente en su sitio.
Empiece con un crawler de escritorio apuntando a su propio dominio. Si es nuevo en este tipo de auditoría, qué hace realmente un crawler SEO explica los fundamentos subyacentes. Una herramienta que respeta robots.txt por defecto le da una vista limpia de lo que es descubrible, incluyendo cada enlace de filtro, cada página paginada y cada URL de variante. Compare esa cifra con el número de productos únicos de su catálogo. Si el crawler encuentra 800.000 URLs y su base de datos tiene 20.000 productos, ya sabe por dónde empezar a mirar.
A continuación, saque el XML Sitemap y compárelo con el rastreo. Las páginas que están en el sitemap pero faltan en el rastreo son huérfanas. Las páginas que están en el rastreo pero faltan en el sitemap son candidatas a desperdicio. Ambas listas merecen atención.
Después, abra Google Search Console y revise el informe Crawl Stats dentro de Ajustes. El informe desglosa las peticiones por propósito (descubrimiento, actualización, error) y por tipo de respuesta. Fíjese en números altos de redirecciones o errores de servidor. Son victorias baratas. Los detalles completos del informe están en la documentación de Crawl Stats de Search Console.
La vista más completa viene de los logs de servidor en bruto. Filtre al tráfico verificado de Googlebot y mire qué URLs reciben más impactos. En un ecommerce típico, las 50 URLs más rastreadas no coincidirán con los 50 productos más importantes. Esa diferencia es el problema del crawl budget en números.
Aquí tiene un resumen rápido de lo que muestra cada método y lo que pasa por alto.
| Método | Fortalezas | Puntos ciegos |
|---|---|---|
| Crawler de escritorio | Inventario completo de URLs, revisión de canonical, detección de duplicados | No dice lo que Googlebot realmente pide |
| Crawl Stats de Search Console | Actividad real de Googlebot, códigos de respuesta, tendencias | Agregado, retrasado, con muestreo |
| Análisis de logs de servidor | Comportamiento exacto de Googlebot, detalle por URL | Requiere acceso a los logs y trabajo de procesado |
Ejecutar los tres en paralelo es la configuración más fiable. Si solo tiene tiempo para uno, empiece con un rastreo de escritorio y coloque Search Console encima.
Arreglos prácticos que mueven la aguja
Con el desperdicio mapeado, puede aplicar los arreglos en orden de impacto. No todo arreglo importa en todos los sitios. El orden de abajo refleja lo que suele ayudar más en un catálogo de ecommerce típico.
Diseñar una estrategia para la navegación facetada
Empiece por su propia analítica. Mire qué combinaciones de filtros reciben tráfico orgánico. En la mayoría de los catálogos, un número reducido de facetas aporta casi todo el valor de búsqueda. “Zapatillas de correr rojas” y “chaquetas de montaña impermeables” pueden tener búsquedas. “Zapatillas medianas rojas impermeables talla 9 de poliéster” no.
Convierta las combinaciones que generan tráfico en landing pages dedicadas. Déles su propia URL, su propio título y descripción, sus propios enlaces internos y un hueco en el sitemap. Bloquee el resto del rastreo por completo. Puede hacerlo con reglas Disallow en robots.txt apuntando a los patrones de parámetros, o cambiando los filtros menos importantes a AJAX que no modifica la URL.
Una opción intermedia es mantener la URL y marcarla como noindex, follow. Eso permite a Google rastrear la página para descubrir nuevos productos por debajo sin añadirla al índice. En catálogos grandes esto sigue gastando crawl budget, así que disallow suele ser la mejor opción para todo lo que no atraiga tráfico.
Tratar las variantes de producto de forma limpia
Elija una variante canónica para cada producto. La que más gente compra, el color neutro o la talla por defecto funciona bien. Apunte cada URL de variante restante a esa canónica con una etiqueta rel="canonical". Eso le dice a Google qué variante mostrar en la búsqueda y consolida las señales en todas ellas.
Cuando una variante concreta tiene su propia demanda de búsqueda real, déle una página dedicada con contenido único. Ese contenido debe justificar la URL separada. Una foto de color diferente no basta. Un caso de uso distinto, información de tallas distinta o un posicionamiento estacional distinto sí pueden.
Para el resto, deje que el comprador elija la variante en una sola página de producto usando JavaScript. La URL se mantiene estable, el crawler la visita una vez y toda la información de variantes vive en el mismo HTML.
Limpiar su sitemap XML para ecommerce
Su sitemap debería contener solo productos que están en stock, son indexables y son canónicos. Quite las entradas que redirigen, devuelven errores o están bloqueadas por robots.txt. Divida el archivo por categoría si pasa de 50.000 productos por sitemap, para que la plataforma siga siendo legible y las fechas lastmod mantengan significado.
Fije lastmod a partir de cambios reales de contenido. Regenerar el sitemap completo cada noche con la fecha de hoy en todas las entradas es un error común. Google aprende a ignorar las fechas que siempre se mueven, y así la señal pierde todo sentido.
Si tiene productos de temporada, devuélvalos al sitemap en el momento en que vuelven a estar en stock. El primer rastreo tras ese cambio es el que decide si el producto atrapa el tráfico temprano de la temporada.
Enlazar a las páginas que venden desde las páginas que se rastrean
Los enlaces internos son la señal más fuerte que puede enviar sobre qué páginas importan. Las páginas que Googlebot rastrea a menudo se convierten en concentradores. Cualquier página enlazada desde un concentrador hereda parte de esa prioridad de rastreo.
Revise su página de inicio, sus tres categorías principales y sus diez productos principales. ¿A qué páginas enlazan? Si un lanzamiento nuevo queda enterrado a cuatro clics de profundidad detrás de la paginación, seguirá sin indexarse hasta que una señal externa lo eleve. Si el mismo lanzamiento se promociona desde la página de inicio y desde la categoría, suele indexarse en un día.
La regla sencilla: los más vendidos y las novedades deben ir cerca de la parte alta de las páginas que Googlebot más visita. Las migas, los productos relacionados y los módulos editoriales son todos herramientas útiles para repartir autoridad de enlaces. Para un análisis más profundo, la lista completa de auditoría técnica de SEO cubre las revisiones de enlaces internos que merecen ejecutarse junto al trabajo de crawl budget.
Cómo supervisar después de la limpieza
Una limpieza solo cuenta si se sostiene. Los catálogos de ecommerce cambian sin parar. Nuevos productos, nuevas categorías, nuevas campañas y actualizaciones de plataforma crean oportunidades para que aparezca desperdicio nuevo.
Mire sus Crawl Stats semanalmente durante el primer mes tras cualquier cambio significativo. La métrica en la que fijarse es la proporción de respuestas exitosas sobre el total de peticiones. Un valor sano está muy por encima del 90 por ciento. Una limpieza que ha reducido el desperdicio debería mover esa proporción hacia arriba en dos o tres semanas, mientras Google se adapta a la nueva forma del sitio.
Haga un seguimiento del tiempo hasta la indexación de los nuevos lanzamientos como indicador adelantado. Publique el producto, anote la hora y observe cuándo aparece en el índice. Antes de la limpieza, eso puede tardar días. Después de la limpieza, debería ocurrir en un plazo de 24 a 48 horas en una tienda típica. Si la cifra no se mueve, sus arreglos no han llegado a las páginas que importan.
Ejecute su rastreo de escritorio una vez al mes. El desperdicio nuevo tiene la costumbre de volver a aparecer. El equipo de marketing activa un nuevo parámetro de seguimiento, un plugin añade un filtro nuevo, una migración deja una cadena de redirecciones detrás. La auditoría mensual captura esto antes de que se acumule en meses de visitas desperdiciadas. Para los flujos de limpieza alrededor del resto del ruido, cómo encontrar y arreglar enlaces rotos encaja de forma natural con la auditoría regular de rastreo.
Por último, agende una revisión más profunda cada trimestre. Reconstruya la lista blanca de facetas, revise el tratamiento de variantes, reevalúe el sitemap y confirme que sus productos principales siguen en el lugar donde deberían estar dentro del grafo de enlaces internos. Una pasada trimestral evita que la limpieza se degrade en otro proyecto de auditoría dentro de un año.
Conclusión
El crawl budget en un ecommerce es un problema estructural, no un fallo aislado. El desperdicio viene de la forma de la plataforma, de los programas de marketing conectados a ella y de la manera en que los compradores necesitan navegar. Nada de eso desaparece. Lo que cambia es si trabaja con la forma o contra ella.
Empiece por la auditoría. Encuentre los seis asesinos en su propio catálogo y anote cuántas URLs está generando cada uno. Arregle primero las fugas más grandes. Revise la limpieza con cadencia mensual para que la siguiente migración o campaña no deshaga el trabajo. A lo largo de un año, el efecto acumulado es la diferencia entre que los productos nuevos se indexen el mismo día y que esperen en la cola durante semanas.
Si quiere una herramienta local para la parte de auditoría, Seodisias se ejecuta en su máquina sin límite de URLs, lo cual importa cuando su catálogo tiene medio millón de URLs por revisar. Combínelo con análisis de logs y una revisión trimestral, y el crawl budget pasa de ser una fuga invisible a un número que puede gestionar de verdad.