Technical SEO #technical-seo
Technical SEO covers everything that affects how search engines crawl, render, and index your site: server response, HTML structure, redirects, sitemaps, structured data, and Core Web Vitals. These guides give you the systems-level view that turns a crawler report into ranking gains.
42 posts

Open-Source SEO Crawlers in 2026: Self-Hosted Alternatives to Screaming Frog
The SEO crawlers whose source is actually open: LibreCrawl, Open SEO Crawler, Apache Nutch and the frameworks behind them. What open-source really buys you, what you trade for it, and when it beats a free desktop tool.

What Is Agentic SEO? A Plain Explanation for 2026
Everyone is saying agentic, few are explaining it. What agentic SEO actually means, how it differs from classic SEO and GEO, what is hype versus real, and the low-regret steps to take today.
Vibe-Coded Sites Have Hidden SEO Defects: Here Is How to Find Them
Sites built fast with AI and no-code tools look perfect in the browser and quietly fail in the crawl. Here are the technical SEO defects vibe coding tends to leave behind, and how a crawler surfaces them.

Google Removed FAQ Rich Results: Don't Rip Out Your Schema
Google killed the FAQ rich result and the Search Console report behind it. That is the SERP feature going away, not the markup. Here is what actually changed and why deleting your FAQ schema is mostly busywork.

Bot Traffic Now Exceeds Half the Web: What It Means for You
Automated traffic has passed human traffic for the first time. Here is what is actually driving it, why most of the panic is misplaced, and what to do about your crawl budget.

The Agentic Web Standards: NLWeb, MCP, and AIPREF Explained
New standards like NLWeb, MCP, and AIPREF promise an agentic web. Here is what each one does, what site owners should do now, and what is just hype.

Organic Traffic Dropped? A Calm Diagnostic Playbook
Your organic traffic fell and the graphs look scary. Here is a calm, step by step way to find the real cause before you change a single thing.

IndexNow Explained: Why Google Doesn't Use It (and Who It Helps)
IndexNow lets you tell search engines a URL changed instead of waiting for a crawl. Here is how it works, why Google ignores it, who actually benefits, and how to set it up in an afternoon.

We Audited the Top 1000 Sites for AI Search Readiness
We checked the top 1000 websites for llms.txt, AI crawler rules, structured data, and sitemaps. Only a third are ready for AI search.

Is GEO Overhyped? What the Backlash Gets Right (and Wrong)
A loud backlash says GEO is dead, a fad, propaganda. Here is what the criticism gets right about the hype, what it gets wrong about the shift, and what actually earns visibility in AI search.
Multilingual llms.txt: How to Structure It for a Multi-Language Site
Your site speaks four languages, so how many llms.txt files do you need? How to structure llms.txt across languages, keep it consistent with hreflang, and avoid feeding AI crawlers only half your content.

Discovered, Currently Not Indexed: Why It Happens and How to Fix It
Google found your pages but will not index them, and they have sat that way for weeks. Here is what 'Discovered, currently not indexed' actually means, how it differs from 'Crawled, currently not indexed', and a crawl-based way to fix the real cause.
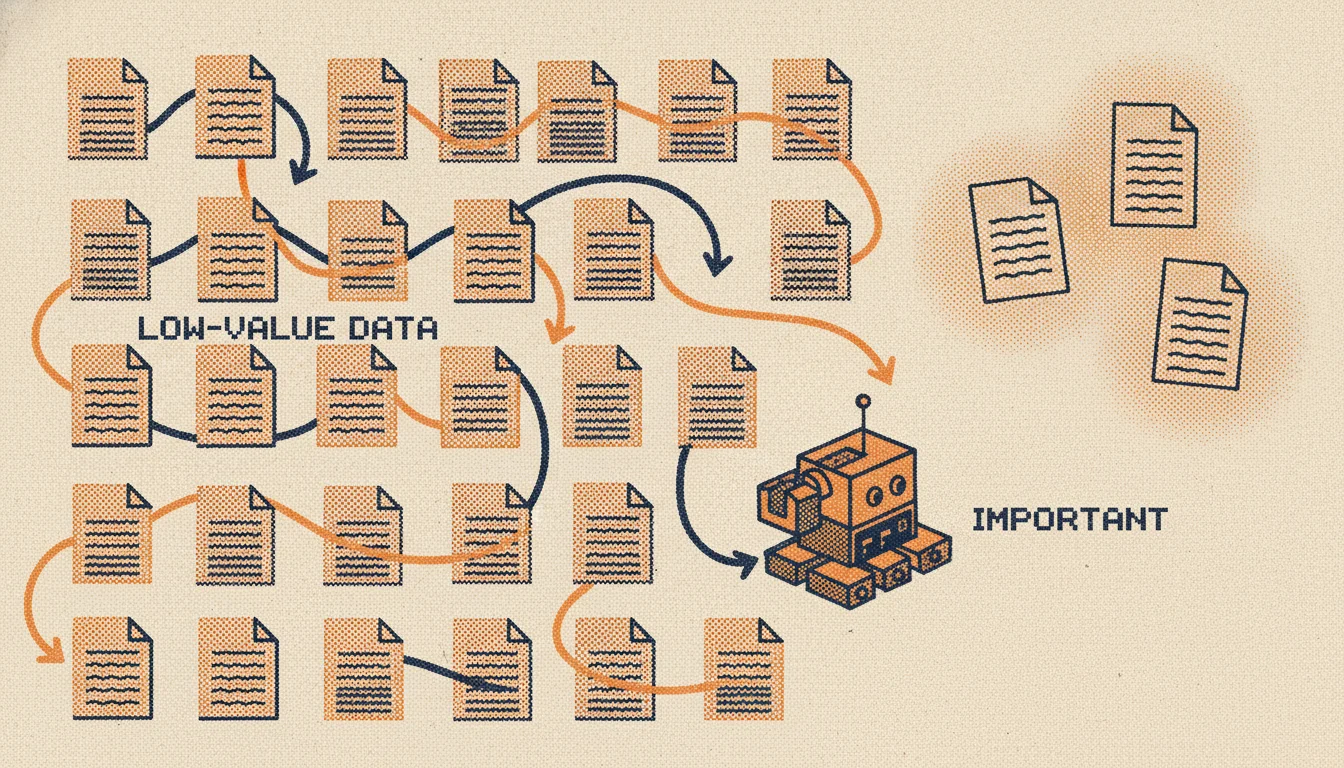
Why Low-Value Pages Get Crawled More (and How to Stop It)
Search engines often spend most of your crawl budget on the pages that matter least. Why low-value URLs attract crawlers, how to find them, and how to redirect that attention to the pages you actually want indexed.

Why DuckDuckGo Is Up 30% (and What It Means for SEO and GEO)
DuckDuckGo installs spiked after Google made AI Search the default. Here is what the search fracture actually means for SEO and GEO, and the channels you should optimize for now.
ai-dataset.json and AI Index Files: Do You Need One in 2026?
A calm look at ai-dataset.json and similar AI index files. What they propose, what AI engines read today, and whether to add one to your site yet.

SEO Crawler for macOS in 2026: What Actually Runs Well on a Mac
Most SEO crawlers were built Windows first. Here is an honest look at which tools run well on macOS today, what Apple Silicon changes, and how to choose without paying for a platform you do not need.